本企画で目指す教材では、アルゴリズムよりもデータ構造に重きを置くと本文で書きました。ですが、データ構造とだけ言ってもわかりにくいかもしれません。そこで、基本的なデータ構造を紹介したいと思います。
まず、一つの値だけを保持するものがあります。これを次のように図示します:

これ以降は、形や詳細はともかく、この「一つの値だけを保持するもの」のいろいろな組合せになります。
それらの最初のものとして、配列を見てみましょう:
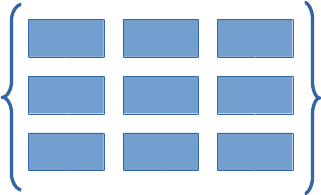
これは、横方向と縦方向に並んだ2次元の配列です。横方向だけ、縦方向だけに並んだ1次元の配列もありますし、3次元以上の配列もあります。先の「普通のバブルソートと普通ではないバブルソート」の後者における “pat” は、3次元配列の例です。また、上の図のように直接的な形での配列に限らず、配列の配列、配列の配列の配列などとして2次元以上の配列を実現する方法もあります。なお、情報にかかわる人は「多次元空間」という言い方を普通にしますが、それはただの配列、とくに4次元以上の配列を指しているだけだったりします。
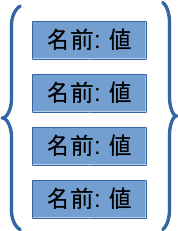
配列は、 “matrix[1][2]” のように、数値の添字で要素を指定します。それに対して、名前で指定するもの、あるいは変数をまとめたものに、レコードがあります。図示すると次のようになるでしょう:
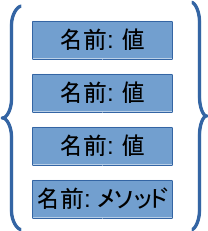
なお、オブジェクト指向の考え方にはいくつかあるのですが、その一つとしてレコードを拡張したものというものもあります。この場合、オブジェクトは次のように書けるでしょう:
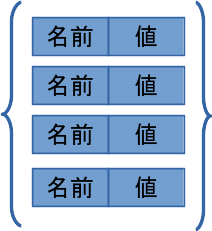
配列やレコードには、すこし特殊なものがあります。配列は “matrix[1][2]” のように数字の添字で要素を指定します。レコードの場合は、 “record.first” のように、レコードの名前と、レコードを構成する変数の名前で要素を指定します。もし、“a["first"]” と書くような、これらが合さったようなデータ構造があったとしたらどうでしょうか。そして、もちろんそういうデータ構造は存在し、連想配列、あるいはハッシュと呼ばれます。これを図示すると、こうなるかもしれません:
次に、すこし複雑になりますが、よく使われるものとして木構造というものがあります:
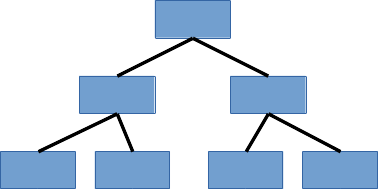
この図では左右のバランスが取れていますが、バランスは取れていなくてもかまいません。
木構造は、要素の親子の関係がはっきりしていますが、その部分をもっと柔軟にすると、グラフというデータ構造になります:
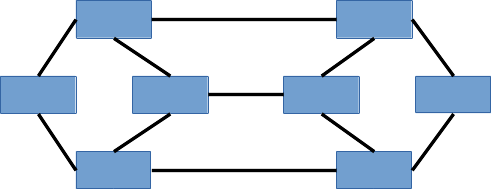
グラフにおける要素間の繋がりには、方向があるものと、方向がないものがあります。
また、要素間の繋がりが輪の形になると、リングになります:
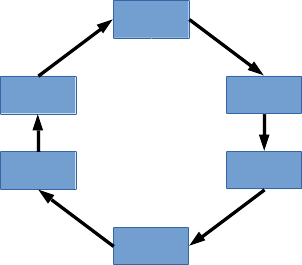
リングは、リング・バッファなど、グルグル回りながらデータを書き換えていったり、データを読み出したりするようなものにも使われています。
リングのどこかを切って、切り口の片方をデータの入口とし、もう片方をデータの出口とすると、キューになります:

これは、「最初に入ったデータが、最初に出る」ということで、“First In, First Out”、略して “FIFO” と呼ばれたりもします。
それに対して「最初に入ったデータが、最後に出る」というデータ構造もあり、スタックと呼ばれています。 “FIFO” に対応するような呼び方としては、“First In, Last Out”、 略して“FILO” などと呼ばれもします:
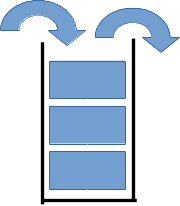
最後になりましたが、重要なデータ構造としてリストがあります。図示すると次のようになります:
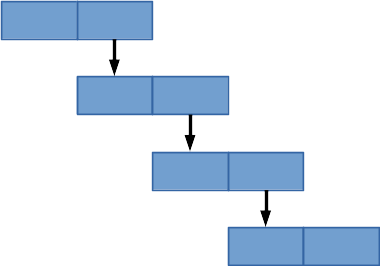
lisp系の言語では、細かい話を除けば、データ構造としてはこのリストしか存在しません。しかし、このリストで、これまで述べたデータ構造の全てを、配列も含めて実現できます。もちろん、配列でも同様に、これまで述べたデータ構造の全てを実現できます。ですが、基本的には、配列はその大きさが固定されています。対してリストは、大きさが可変だという特徴があります。
これらはあくまで基本的なデータ構造、あるいはその概略です。これらをどう用いるかにはかなりの自由度があったり、あるいは目的に対して向き不向きがあったりもします。これらのデータ構造に親しむことで、どのようなデータ構造とアルゴリズムの組合せでプログラムを書くと問題を解き易いのかがわかりやすくなったりもします。言い換えれば、アルゴリズムのみを考えることでプログラミングを行なうことはできないとも言えます。
本企画においてデータ構造を重視するのには、そのような理由があります。アルゴリズム一辺倒でのプログラミング教育は、はっきり言えば誤った方向を向いていると言えるでしょう。
